
Conocí a Frank un 11 de Junio del 2014.
Me acuerdo la primera vez que entró en nuestra pequeña oficina que por aquel entonces teníamos en la calle Maisonnave de Alicante. Era un tio alto, tímido y se le notaba nervioso al ser su primer día como becario en una empresa nueva.
Por aquel entonces, eso del SEO era un término que nisquiera conocía y seguramente no tenía ninguna intención de aprenderlo.
Pero por suerte o desgracia, llegó en una época de mucho cambio y crecimiento en la que todos los que estábamos en la oficina, teníamos que hacer de todo.
Así que le tocó echar una mano con el SEO.
Me acuerdo que sacamos hueco un viernes por la tarde para sentarnos durante unas horas y le enseñé la base de lo que necesitaba que aplicase a partir de ese momento a algunos proyectos de clientes. (Eso sí, solo los más pequeños, por si acaso..) ;)
Me sorprendió su proactividad, su capacidad de trabajar y su manera de analizar tan metódica que tenía.
A la semana noté que lo que le enseñé ese viernes por la tarde, se le estaba quedando pequeño. Tenía hambre de más. Estaba empezando a engancharse al SEO de la misma forma que empezamos los yonkis del SEO en nuestros principios.
Ha tenido tal evolución durante los últimos años, que puedo decir, sin miedo a equivocarme, que en estos momentos está a la altura de los mejores SEOs técnicos de este país.
Tal cual.
Te dejo con el MEGA post de un SEO que en su día iba para abogado y que por el camino se llevó un título de Mister Murcia 2009. Casi ná!
 Mi nombre completo es Francisco Mateo Guilabert, aunque algunos amigos me conocen cómo Frank Mabert. Nací en Cox (Alicante) y trabajo como Analista y Consultor SEO en Dropalia desde junio de 2014. Mi pasión es la vertiente semántica del SEO, el diseño de arquitecturas web optimizadas y el análisis minucioso de la intención de búsqueda de los usuarios en Google.
Mi nombre completo es Francisco Mateo Guilabert, aunque algunos amigos me conocen cómo Frank Mabert. Nací en Cox (Alicante) y trabajo como Analista y Consultor SEO en Dropalia desde junio de 2014. Mi pasión es la vertiente semántica del SEO, el diseño de arquitecturas web optimizadas y el análisis minucioso de la intención de búsqueda de los usuarios en Google.
Gracias a Alex he podido aprender en poco tiempo lo que a otros lleva años. A él y a José Ignacio, les debo la oportunidad de poder aprender esta profesión que amo. Eso y mucho más.
El día que asumí el reto de escribir este post Alex me dijo francamente: “si escribes una m***** ni sueñes que lo publique”. Si finalmente estás leyendo estas líneas prepárate, porque quizá lo que tienes delante te puede interesar mucho.
Este artículo tiene 2 partes.
1ª parte. Guía Anti-Canibalización paso a paso, para usuarios no avanzados.
Con un lenguaje sencillo, te doy las pautas para detectar si tu web tiene contenidos canibalizados y un método para vencer a la Canibalización.
2ª parte. Dirigida a profesionales con conocimientos SEO avanzados.
Te voy a contar mis descubrimientos sobre la Canibalización SEO y a darte un método eficaz para optimizar tus proyectos o los de tus clientes.
Además, este artículo es también la historia de un caso de éxito; el del diseño de una arquitectura web Anti-Canibalización para un ecommerce, cuyos resultados pueden verse en la gráfica.
Si decides lee este post al completo, te contaré todo lo que durante el proceso he aprendido acerca de:
- Cómo detectar si a tu web la está matando la Canibalización SEO y el método para vencerla. (1ª parte para usuarios no avanzados)
- Qué es de verdad la Canibalización SEO (2ª parte para usuarios avanzados)
- Cómo optimizar la densidad de KWs de los textos correctamente para que no se canibalicen (2ª parte para usuarios avanzados)
- Cómo es posible tener 2 resultados en 1ª página de Google sin que se canibalicen (2ª parte para usuarios avanzados)
Guía Básica para detectar y vencer la Canibalización SEO (1ª Parte)
Aquí comienza la guía básica para usuarios no avanzados.
La Canibalización SEO* sucede cuando dentro de tu web “hablas varias veces de lo mismo”.
Como consecuencia unas páginas de tu web se acaban “comiendo” la fuerza de otras y no consigues posicionarte todo lo bien que deberías con ninguna de ellas.
*(Esta es una definición simplificada, ya que el asunto es más complejo y prefiero explicarlo en detalle en la 2ª parte).
Antes, te voy a indicar una Guía Paso a Paso para tanto si tienes un blog como si tienes una tienda online.
Paso 1. Averigua si tienes contenido duplicado
Voy a empezar contándote mi método infalible para detectar contenido duplicado que se está canibalizando. Hay otros métodos, pero este es mi favorito. Por desgracia, para ello utilizo una herramienta de pago, pero no te preocupes porque tras explicarte cómo detectarlo con Ahrefs, te doy un método alternativo fácil y gratuito.
Ahrefs es una herramienta de monitorización de KWs profesional. Gracias a ella puedes identificar entradas y salidas violentas de KWs. Te muestro un ejemplo. Observa que en un mismo día la KW “faldas largas” sale de una URL y pasa a estar posicionada por otra URL.

Lost indica cuando una página de tu web ha dejado de estar posicionada para una KW.
New indica cuando una página de tu web ha empezado a estar posicionada para una KW.
(Si tienes Ahrefs, puedes llegar ahí seleccionando Organic Search > Organic Keywords > Movements)
Que en un mismo día una KW entre y salga de páginas distintas es un síntoma de que Google no sabe bien qué página de la web de ZARA ofrecer cuando le preguntan por “faldas largas”.
ZARA es un gigante y puede permitirse esos errores por la autoridad de su dominio. NO cometas estos errores en tu web o no se posicionará NUNCA.
Si ZARA evitara la Canibalización sería fácilmente 1ª para esta KW (y para muchas otras) en lugar de conformarse con la posición 8 o 9. Amancio llámame ;)
¿Cómo puedes llegar a conclusiones similares sin tener esta herramienta? Este es el método FÁCIL y totalmente gratuito.
Ve a tu navegador y escribe site:nombredetuweb.com + “palabra clave”
En el lugar de “palabra clave” pon aquella palabra clave o concepto que sospechas puede estar repetido en varias ocasiones a lo largo de toda tu web.
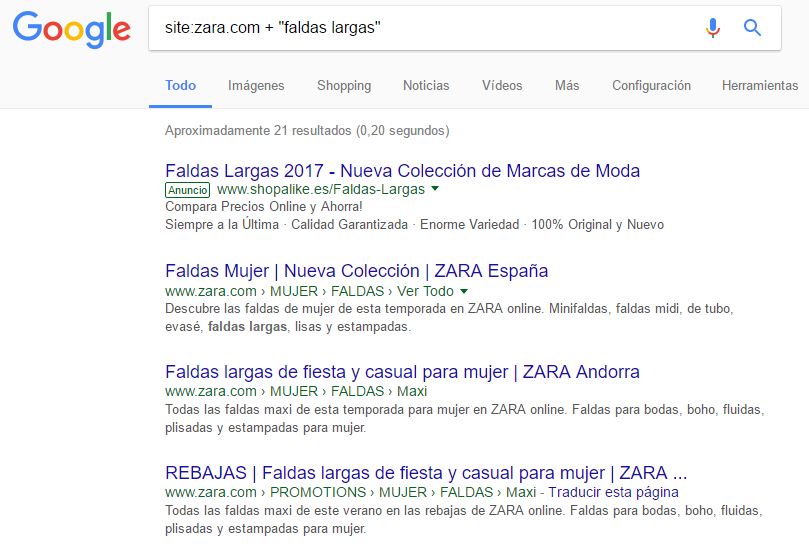
Como ves en la imagen, aparecerán todas las páginas de tu web que hablan acerca de esta palabra clave. Normalmente, la primera URL será la principal y más importante, aquella que mejor tienes posicionada. Debes preguntarte si las otras URLs tienen un contenido diferente o si por el contrario son muy similares a la primera.
¿Aportan una información diferente o van destinadas a satisfacer la misma intención de búsqueda de que la primera? Te cuanto como averiguarlo!
Paso 2. Elimina duplicidades en la arquitectura de tu web
Si como resultado de la prueba has descubierto que tu web tiene contenido duplicado, sigue estos consejos para eliminar los problemas que causan los duplicados más frecuentes.
a) Tags y categorías
Una de las formas más fáciles y frecuentes de canibalizar es con las tags y las categorías. Muchos, movidos por el ímpetu inicial de etiquetarlo y categorizarlo todo, crean, sin ser conscientes, cientos de páginas débiles y de contenido escaso.
La forma más sencilla de evitar este problema es instalar Yoast SEO y poner las páginas de tags y categorías en noindex.
PRECAUCIÓN: antes de poner tags y categorías en noindex asegúrate (bien con Analytics, bien con Ahrefs o Semrush) de que las páginas que vas a desindexar no te aportan ningún tipo de tráfico significativo.
¿Por qué noindex para tags y categorías? Porque quiero que evites son estos errores.
Imagina que tienes la web ibericosmanolo.com (nombre inventado) con las siguientes URLs:
Ibericosmanolo.com/jamon-iberico (categoría de la tienda online)
Ibericosmanolo.com/tag/jamon-iberico (etiqueta del blog)
Ibericosmanolo.com/categoria/jamon-iberico (categoría del blog)
Sin darte cuenta ya hay 3 páginas en tu web “hablando de lo mismo” a ojos de Google.
Consejo adicional: para evitar que Google malgaste su presupuesto de rastreo también puedes y debes bloquear con robots.txt estas páginas de tags y categorías. De esa forma Google podrá concentrar su rastreo en otras páginas de tu web que sí quieres indexar y posicionar.
Es cierto, que hay excepciones en las cuales las tags y categorías funcionan muy muy bien, si tienen un enfoque estratégico, sí agrupan muchos post de calidad y si el dominio tiene autoridad. Hasta que tu web no esté en ese punto, por favor, primero meta noindex y después bloqueo por robots.txt.
b) Elimina duplicidades semánticas
Simplificando mucho, esto es así de fácil:
- Si tienes un blog o web informativa, asegúrate de que, a ojos de Google, solo hay un lugar para informarse sobre cada cosa.
- Si tienes una tienda, asegúrate de que, a ojos de Google, solamente hay un lugar en tu web donde comprar esa cosa.
El error más frecuente en muchos blogs o webs informativas es la creación de varias publicaciones sobre la misma temática sin un enfoque diferente (técnicamente dicho, sin satisfacer una intención de búsqueda diferente).
El error más frecuente en tiendas es la posibilidad de poder comprar lo mismo en distintas secciones de la web (recordemos el caso de ZARA y las “faldas largas”).
En caso de tiendas online con blog, es posible tener publicaciones similares que no se canibalicen, si se hace bien. Por ejemplo, puedes tener una publicación del blog que hable de cómo elegir el mejor jamón ibérico y una página en la web para comprar jamón ibérico.
Google podrá diferenciar que tienes dos URLs:
- Una para vender Ibericosmanolo.com/jamon-iberico, que satisface una intención de búsqueda transaccional.
- Una para informar Ibericosmanolo.com/como-elegir-el-mejor-jamon-iberico, que satisface una intención de búsqueda informativa.
El error será si tienes:
- Ibericosmanolo.com/jamon-iberico (tienda online)
- Ibericosmanolo.com/blog/comprar-jamon-iberico (blog)
En tal caso Google puede entender que ambas páginas sirven para comprar, y por lo tanto se canibalizarían.
O si tienes:
- Ibericosmanolo.com/como-elegir-el-mejor-jamon-iberico (blog)
- Ibericosmanolo.com/elije-siempre-el-mejor-jamon-iberico (blog)
En este caso Google puede entender que ambas páginas informan de lo mismo, y por lo tanto se canibalizarían.
c) ¿Qué opciones hay para solucionarlo?
- Fusión.
Haz una lista de todas aquellas páginas duplicadas. Identifica cuál de todas las es la que más tráfico te aporta (URL fuerte) y vuelca en ella el contenido de las demás URLs. Recuerda hacer un 301 de las URLs que elimines.
- Eliminación de URLs de duplican.
Si crees que la URL fuerte contiene toda la información y que la información de las otras URLs secundarias no aporta nada nuevo, elimina las URLs duplicadas. Recuerda también hacer los 301s.
- Noindex.
En el caso de que no quieras o no puedas borrar las publicaciones que duplican, ponlas en noindex.
- Canonical de las URLs débiles a la fuerte.
Establecer una URL canonical es otra opción en el caso de que no quieras o no puedas eliminar las URLs que duplican.
Según mi experiencia, la opción de las canonicals es la peor y la menos efectiva. Google, en ocasiones, se hace un lío y pasa olímpicamente de los canonicals (Si alguien tiene una teoría de porqué Google pasa en ocasiones de las canonicals y quiere exponerla en los comentarios, será bienvenida)
Por favor, si puedes fusionar, eliminar o ponerlo en o ponerlo en noindex, hazlo.
PRECAUCIÓN: de nuevo recuerda que antes de poner una página en noindex o de eliminarla debes de asegurarte (ya sea con Analytics o con otras herramientas) de que no te traen un volumen de tráfico importante. Y de que, si eliminas páginas que te traen tráfico,por poco que sea, haces correctamente un 301s.
Paso 3: Diseña una estructura jerarquizada
Este apartado daría para una publicación en sí misma. Ya has oído hablar de la estructura silo y de su importancia.
En el caso de MyKaramelli, cuando nos llegó tenía una estructura en la cual categorías
principales, subcategorías y productos partían de la URL raíz, como puedes ver en la captura.
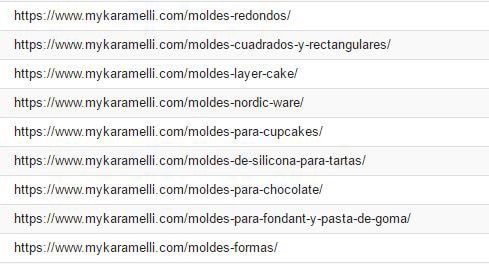
Es tan solo un ejemplo. Te puedes imaginar que la web es mucho más grande.
El problema de estas estructuras (sin jerarquía) es que impiden que Google sepa averiguar con facilidad que URL ofrecer. Así, para la búsqueda “moldes de repostería” todas las URLs partían de salida con la misma jerarquía.
ACLARACIÓN: soy consciente de que todavía hay quien defiende la tesis contraria, es decir, que mejor que todas las URLs partan de la raíz, y que mejor cuanto más pegada al dominio esté la KW.
Hay casos y casos. Yo te hablo desde mi experiencia y desde los resultados obtenidos.
Este es un ejemplo de la nueva arquitectura de URLs que diseñe para MyKaramelli.
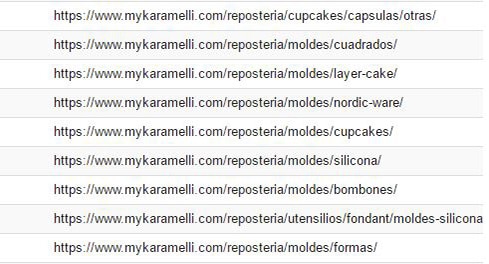
Con el resultado final, Google es capaz de averiguar con facilidad que, para la búsqueda “moldes de repostería” sólo hay una URL posible: www.mykaramelli.com/repostería/moldes/ y que el resto de URLs dependen jerárquicamente de esta y están destinadas a satisfacer búsquedas más específicas.
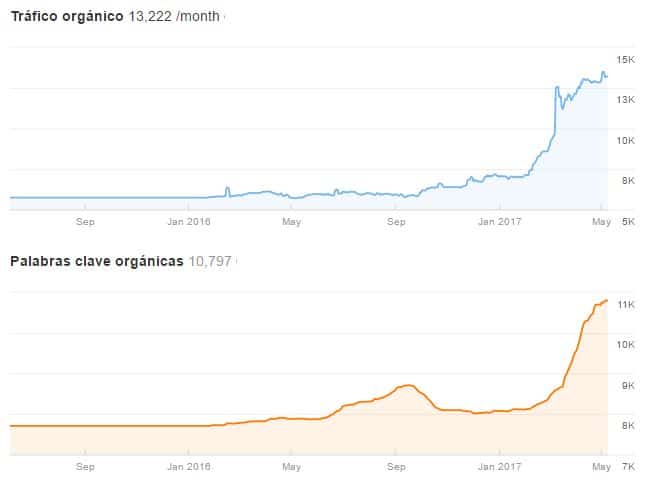
El resultado de todo el aprendizaje que te he narrado desde el comienzo, se resume en estas dos gráficas con la que abrí el artículo.
La gráfica naranja se refiere al número de KWs posicionadas. En ella observa la pérdida de KWs indexadas a consecuencia del cambio de estructura y la recuperación progresiva. Durante un tiempo Google debe “reaprender” en que sitio está todo.
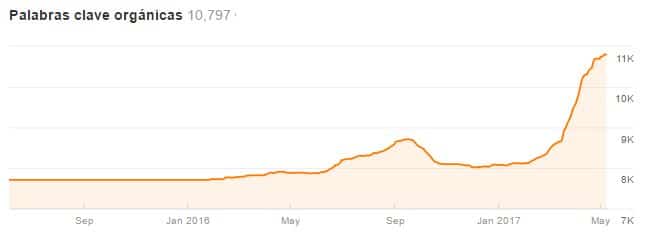
Tras este proceso, que requiere de paciencia, los resultados son asombrosos, como puede verse en la gráfica de tráfico estimado de Ahrefs que viene a continuación.
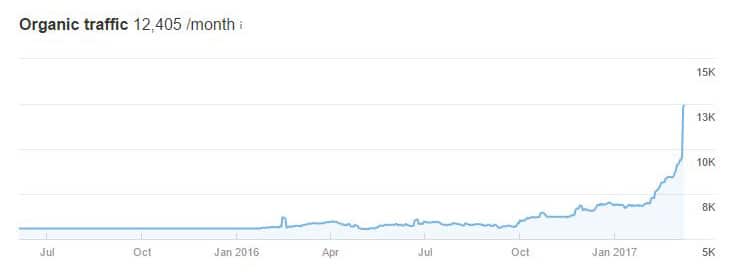
Como a menudo muchos nos acusan a los SEOs de tener Semrushitis o Ahrefendesitis, también aporto una gráfica del tráfico real de este proyecto.
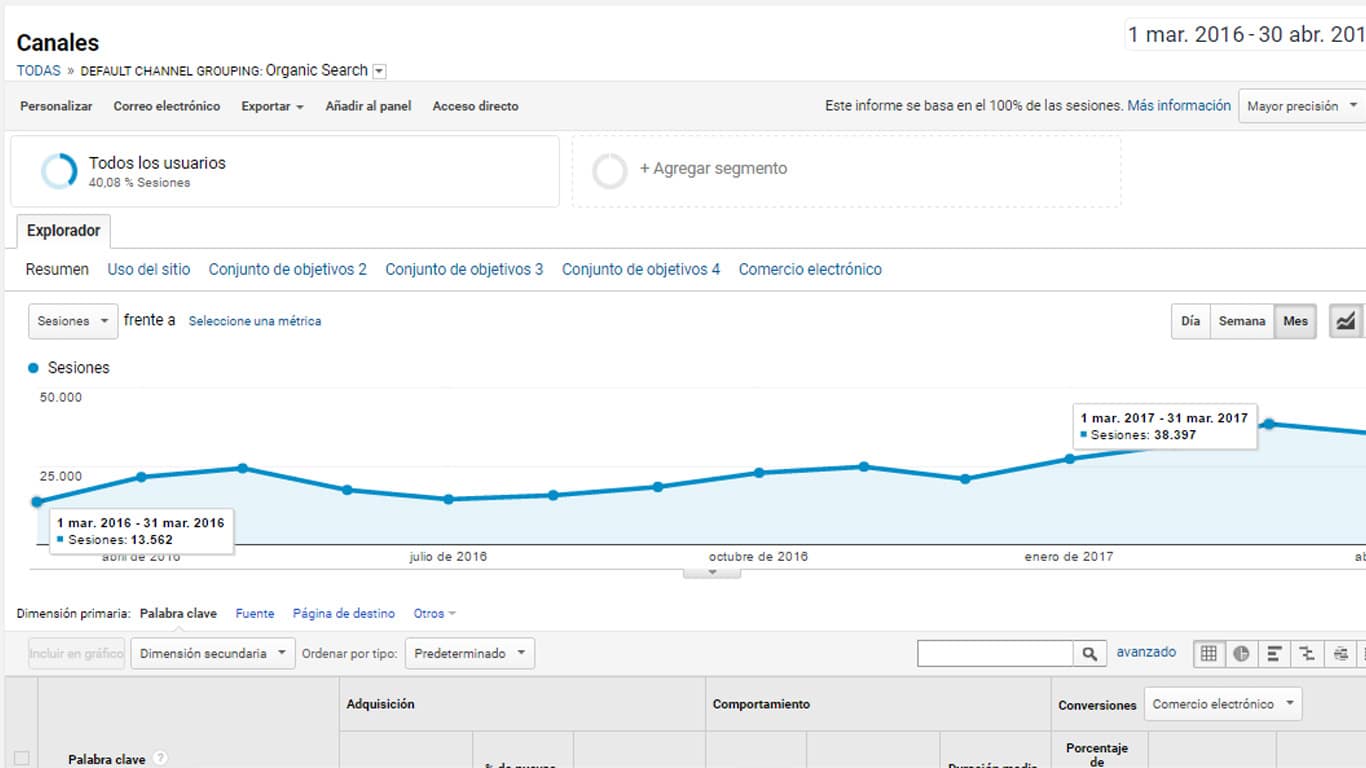
Como puede verse, se ha pasado de 13.562 sesiones (marzo de 2016) hasta un pico de 38.397 sesiones (marzo de 2017). Con lo cual las estimaciones de tráfico de Ahrefs se quedan, en este caso, cortas.
Aquí termina la primera parte dedicada a usuarios no avanzados. Ahora da comienzo la segunda parte, la más heavy metal.
¿Qué es de verdad la Canibalización SEO? (2ª parte)
Al contrario de lo que hemos pensado durante un tiempo, lo que genera contenido duplicado y lo que realmente canibaliza no son las KWs, sino las “intenciones de búsqueda” o search intents (utilizaré esta segunda expresión por ser más corta)
No se puede decir que dos páginas compiten por una misma KW, porque una KW tiene tantas caras como search intents relacionados con esa KW.
Es más correcto decir la Canibalización sucede cuando hay varias páginas de nuestra web compitiendo entre ellas por un mismo search intent.
Repito:
“una KW tiene tantas caras como search intents relacionados con esa KW […] la Canibalización sucede cuando hay varias páginas de nuestra web compitiendo entre ellas por un mismo search intent.”
Tipos de search intents
Para entender la fórmula es necesario recordar claramente los distintos tipos de search intent.
Existen tres tipos principales y uno mixto:
- Informativo: el informativo es el search intent que satisface la necesidad de información de los usuarios.
- Transaccional: el transaccional es el search intent orientado a realizar una acción, como comprar algo, contratar un servicio o utilizar una herramienta online. (Ej: “comprar corbatas”, “abogados en Madrid” o “software para enviar un mailing”)
- Navegacional: la navegacional es aquella búsqueda que se realiza en Google en lugar de escribir una web con sus www…, es decir, la búsqueda de la pereza (Ej: “Facebook”, “Mercadona”, etc.) Estadísticamente, el único objetivo del usuario es acabar en la web oficial, pero lo hace pasando por Google. No nos interesa para este artículo.
Hay un 4ª search intent de carácter mixto, a caballo entre el informativo y el transaccional.
- Investigación comercial: se trata de búsquedas en principio informativas pero que pueden finalizar en transacción. El contenido que satisface este search intent aclara dudas sobre la adquisición de un producto o servicio o puede ser una comparativa entre varios productos y servicios.Es el tipo de search intent por excelencia en las webs de nicho que monetizan con afiliados. Aclaran dudas y ofrecen al usuario la oportunidad de realizar una transacción (Ej: “iphone 7 plus o samsung galaxy s7 edge” o “prestashop o magento”).
El Canibalismo del Search Intent Vs Canibalismo de Keywords
El canibalismo de KWs solo se puede en aquellas KWs cuyo search intent es homogéneo (siempre el mismo).
En webs estrictamente “informativas” existe canibalismo de KWs porque el usuario siempre quiere a informarse en relación con una KW. Por lo tanto, querrás asegurarte de que ese search intent solo se ve satisfecho en un lugar de tu web. O de que hay un lugar claramente definido como el principal.
En webs estrictamente “transaccionales”, también puede existir canibalismo de KWs. Si tienes una tienda online (sin blog) donde solo se puede comprar, querrás asegurarte de que solo hay un lugar donde se puede “comprar esa KW”. O de que hay un lugar claramente definido como el principal.
Al margen de estos ejemplos, cualquier ecommerce tiene una dualidad de search intents, ya que pueden satisfacer tanto la fase informativa como la fase la transaccional de la búsqueda de una KW.
El GRAN PROBLEMA, cómo estás pensando, es la ambigüedad de algunas KWs.
Alguien que busca en Google, por ejemplo, “crear un blog” ¿se quiere informar de cómo hacerlo o sabe cómo hacerlo y quiere realizar la acción? ¿Search intent informativo o transaccional?
Las KWs con dos search intents
Te habrás fijado que, para algunas búsquedas, Google te ofrece en el top10 un mix de tiendas online, blogs, foros…
La razón es que se trata de KWs ambiguas en las cuales el search intent no está claro, por tanto Google ofrece un mix de páginas que satisfacen distintos search intents.
Vemos el ejemplo de la KW “diseñar una web”. Nos encontramos un mix de resultados informativos y transaccionales. Por un lado guías tipo how to (“cómo crear…”) y, por otro, webs en las cuales se puede realizar la acción de crear un blog (como Wix o Jimdo).
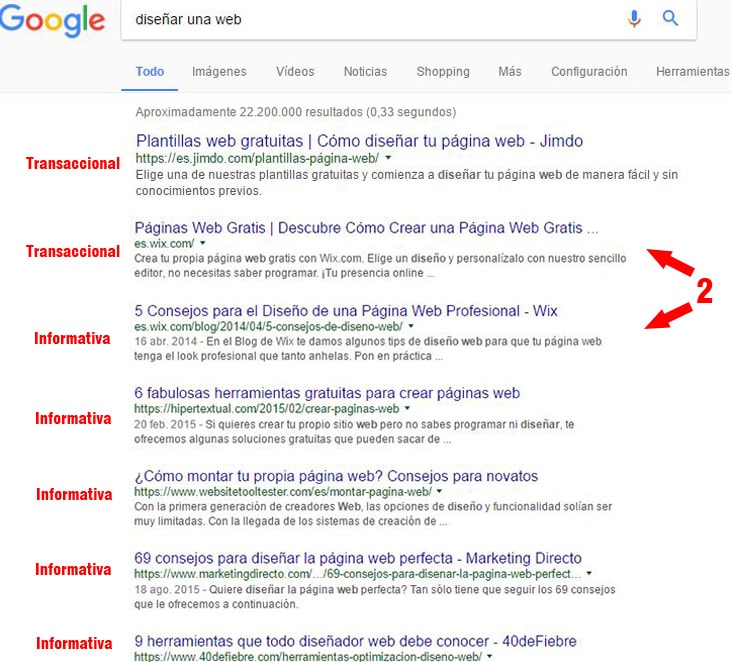
Dos resultados en 1ª página de Google ¿Cómo es posible?
¿Te has fijado bien en la captura anterior? Un mismo dominio (wix.com) tiene dos resultados en 1ª página. Si fuera cierto que las KWs se canibalizan no sería posible rankear dos URLs en 1ª página para una misma KW ¿cómo sucede?
La mecánica que lo hace posible es que al tratarse de una KW ambigua, Google no sabe todavía si quieres consejos para crear una web o una plataforma para crear una web.
Pero wix.com lo ha hecho de forma excelente (no sé si de forma intencionada o no) para garantizarse la 2ª y la 3ª posición para esta búsqueda.
¿Qué es lo que ha hecho Wix de forma excelente?
Tiene una página para cada search intent. Una página satisface el deseo de información y la otra el deseo de transacción.
¿Necesitas más pruebas? Otro ejemplo, para la búsqueda “enviar mailing” vemos repetido el mismo patrón, con Mailfy obteniendo dos posiciones en 1ª página para dos URLs distintas. La primera de ellas dirigida a un search intent informativo y la segunda a un transaccional, la propia herramienta de envío de mailings.
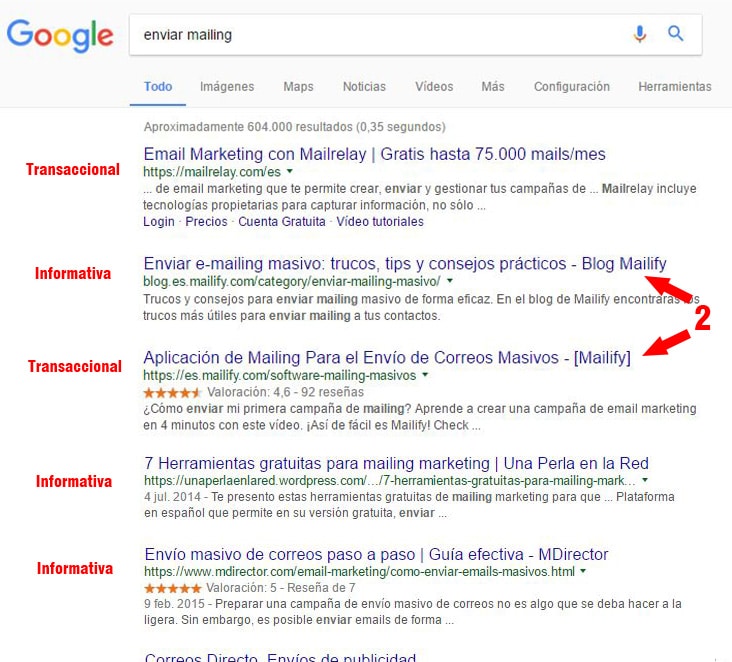
Prestemos atención a la primera URL. Se trata de la URL de una categoría.
http://blog.es.mailify.com/category/enviar-mailing-masivo/
Cómo comenté en la primera parte soy partidario de poner en noindex tags y categorías en blogs que están empezando para evitar que haya URLs con contenido escaso, que duplican y que pueden canibalizar. Y decía que había excepciones. Esta URL es un ejemplo. Aglutina 131 post relacionados con “enviar mailing” lo cual puede satisfacer de forma excelente una search intent informativo del usuario en relación a esta palabra clave.
Volviendo al tema importante!
Las ventajas de crear una página para cada search intent son enormes!:
- Abre la posibilidad de tener 2 resultados en 1ª página.
- Permite crear páginas informativas exhaustivas, como no puede hacerse cuando se trata en una página destinada a la conversión (como por ejemplo una página de producto o ficha de producto en un ecommerce).
- Permite crear páginas totalmente optimizadas para la conversión sin la necesidad de meter con calzador textos para optimizar el on page y la densidad de KWs de esa página.
A pesar de estas ventajas, tener dos páginas dedicadas a una misma KW, repartiendo un search intent para cada una, puede tener desventajas como:
- Una doble inversión en linkbuilding, lo cual se puede paliar con un buen enlazado interno.
- No se me ocurre ninguna más (lo cual no quiere decir que no las haya).
Hay casos, como las webs de nicho que monetizan con afiliación, en los cuales quizá sí que conviene tener una sola página, ya que suelen satisfacer el search intent mixto de la investigación comercial, es decir: información + transacción.
El nuevo arte de la desambiguación de KWs y la optimización de contenidos
Todos conocemos el funcionamiento de herramientas como SEOlyze, OnPage.org o Xovi (por citar algunos ejemplos) para optimizar la densidad de KWs de una página.
¿Cuál es el error que durante un tiempo hemos estado cometiendo en su uso?
Hemos cometido el error de optimizar la densidad de KWs de páginas que satisfacen bien un search intent informativo, bien un search transaccional, para una KW ambigua.
Todos queremos rankear por las KWs con más volumen de búsqueda, el problema es que, en algunas ocasiones, estas KWs son totalmente ambiguas.
Las SERP que surgen como resultado de la búsqueda de una KWs ambigua NO son fiables como referencia para la optimización de la densidad de KW de un texto.
¿No te ha pasado que si analizas la densidad de KW del 1º SEOlyze te puede decir que está sobreoptimziado o que le faltan KWs importantes? ¿Cómo es posible?
Prueba de que es cierto es que, para la KW “crear un blog” el 1º no está optimizado, ya que en teoría le faltarían tres palabras importantes. Puedes hacer tu mismo la prueba en esta u otras KWs.
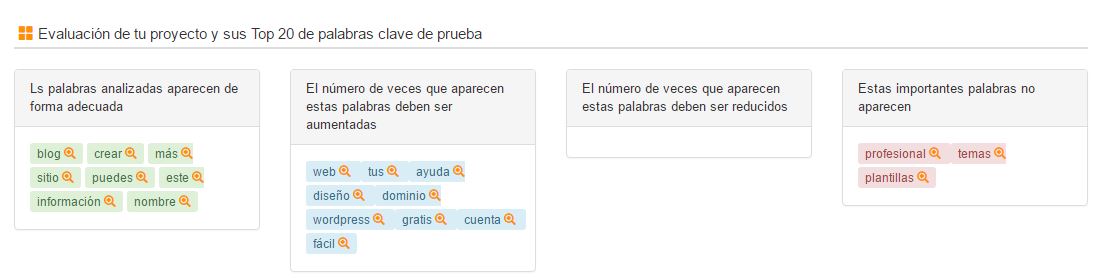
El problema no es de las herramientas. El problema es que hemos utilizado estas herramientas para KWs ambiguas…
Al tratarse de KWs ambiguas Google ofrece en el top10 un mix de search intents (páginas informativas y páginas transaccionales), y quizá la página que queremos optimizar es solo informativa (un post de blog) o es solo transaccional (una categoría de producto de una tienda online)…Como se suele decir coloquialmente, estamos mezclando peras con manzanas…
¿Cómo optimizar la densidad de KWs correctamente?
Tenemos varias opciones. Pongamos caso práctico. KW: “Coches deportivos”
Se trata de una KW ambigua, porque Google todavía no sabe si nos queremos comprar un coche deportivo o si lo que queremos es información sobre los coches deportivos.
Opción 1: Optimización para la KW desambiguada.
Deja la KW “coches deportivos” a un lado. NO optimices la densidad de KW en base a esa KW porque es ambigua. En su lugar.
a) Si tienes una página que satisface un search intent informativo (es decir que tiene información sobre los mejores coches deportivos) hay que realizar la optimización de densidad según la KW “mejores coches deportivos” (y relacionadas).
b) Si tienes una página que satisface un search intent transaccional (es decir donde se pueden comprar coches deportivos) hay que realizar la optimización para la KW “comprar coches deportivos” (y relacionadas).
Es sencillo, peras con peras y manzanas con manzanas.
Opción 2: Optimización para el que reankea más alto en la KW ambigua en nuestro search intent.
Haz la búsqueda de la KW ambigua (“coches deportivos”) en Google y manualmente, con SEOQuake, compara la densidad de tu página con la densidad de la página que -teniendo el mismo search intent que la tuya-, reankea más alto.
a) Si tienes una página que satisface un search intent informativo. Optimiza en densidad como el resultado informativo que esté más alto en la KW ambigua.
b) Si tienes una página que satisface un search intent transaccional. Optimiza en densidad como el resultado transaccional que esté más alto en la KW ambigua.
Search Intent según el rango de precios
Este mismo método es también aplicable a otros parámetros tales como el search intent en el precio.
Un ejemplo. La KW: “coches deportivos”
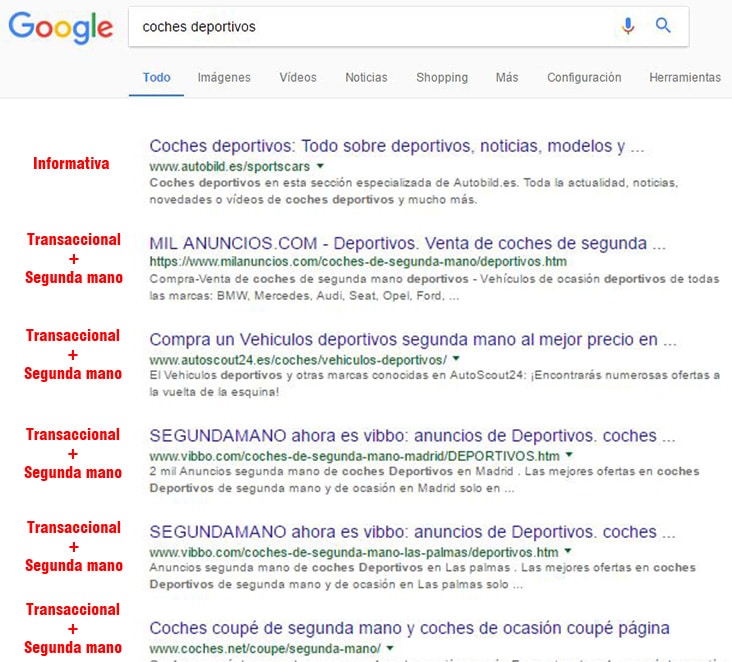
Dentro del top 10 Google nos ofrece, principalmente, coches deportivos de segunda mano. Llama la atención que, pese a ser una búsqueda de KW ambigua, Google ofrece resultados muy específicos. Esto parece indicar una tendencia de los usuarios hacia la segunda mano.
La KW “coches deportivos” tiene por tanto el search intent predominantemente transaccional + rango de precios precio bajo.
Si tienes una página de deportivos de alta gama nuevos, no querrás cometer el ERROR de optimizar la densidad de KW en base al Top 10 de las SERP de “coches deportivos”.
Debes optimizar la página en base a LO QUE ES DE VERDAD, aunque sea admitiendo que, el techo de posicionamiento de tu página para una búsqueda está alejado de la 1ª posición, porque el search intent principal de la búsqueda no coincide con el search intent que tu página satisface.
Ponerle a tu página de coches deportivos de ultralujo el “disfraz” de página de coches deportivos baratos (a través de la densidad de KWs) solo para ser invitado a la fiesta del Top 10, no solo no funcionará, sino que te puede ocasionar más perjuicios (en forma de rebote, por ejemplo) que beneficios.
Y esto es aplicable a cualquier nicho. Creo, personalmente (y no soy el único loco que lo cree), que en los próximos años veremos como el SEO consiste cada vez más en el comportamiento del usuario y cada vez menos en enlaces.
Me alegra que hayas llegado hasta el final. Espero te haya resultado interesante y te ayude a lidiar con la Canibalización SEO. Estaré muy feliz de conocer tu opinión y tu experiencia en los comentarios.
Asimismo, si te apetece, te invito a que sigamos en contacto en los blogs de Dropalia donde -como ya conoces- trabajo como analista y consultor SEO-, el de TráficoIntenso -donde comparto otras opiniones y experiencias profesionales- y en mi web personal frankmabert.com donde compartiré otra serie de pensamientos y experiencias.
Muchas gracias!!!

Como de costumbre quiero cerrar este post presentándote una nueva startup española MUY interesante.
Creo que a estas alturas todos sabemos que el tráfico es super importante para el SEO. Y que mejor manera de conseguirlo que a través de tecnologías como Whatsapp y Messenger.
Probé esta herramienta hace un año, cuando aún era una beta y la verdad es que me dejó LOCO. Échale un vistazo, que si haces SEO, esto te interesa:
Eso es todo amigos. Si te ha gustado este artículo, compártelo desde aquí mismo:
La Verdad Sobre la Canibalización SEO + Guía Para Vencerla -> https://t.co/TCpthpZrhn
— Alex Navarro (@vivirdelared) 15 de mayo de 2017
UN saludo! :)